

Is RisingWave the Next Apache Flink?
Unveil the distinctions between RisingWave and Apache Flink in this blog. While Flink is a big data engine, RisingWave shines as a cloud database, offering unique capabilities. Explore their differences and why RisingWave is not positioned as the next Flink yet excels as a powerful data management solution.
Two weeks ago, we open-sourced RisingWave, a cloud-native streaming database. And in no time, the project gained lots of attention from the open-source community and became the #1 trending project written in Rust!
We're thrilled that RisingWave is gaining interest from the open-source community. Because we're on a mission to democratize stream processing — to make stream processing simple, affordable, and accessible! One more exciting detail: we're building this cloud-native streaming database from scratch.
You're right. There are many streaming systems in the market, and during the last decade, we've seen an abundance of them. Then why did we build another streaming system? One common question from the community is: How is RisingWave different from Apache Flink? And this blog is all about that — a simplified, digestible guide from a developer’s perspective.
 Github Trending: https://github.com/trending/rust?since=weekly (screenshot captured on April 17th, 2022)
Github Trending: https://github.com/trending/rust?since=weekly (screenshot captured on April 17th, 2022) Github Trending: https://github.com/trending/rust?since=weekly (screenshot captured on April 17th, 2022)
Github Trending: https://github.com/trending/rust?since=weekly (screenshot captured on April 17th, 2022)What is Apache Flink?
Apache Flink, known initially as Stratosphere, is a distributed stream processing engine initiated by a group of researchers at TU Berlin. Since its initial release in May 2011, Flink has gained immense popularity in both academia and industry. And it is currently the most well-known streaming system globally (challenge me if you think I got it wrong!).
As one of the early contributors who participated in the initial design of Flink’s stream processing framework (also known as Stratosphere Streaming), I witnessed the growth and evolution of this project over the last decade.
 My proposal on Stratosphere Stream (submitted in 2014) My proposal on Stratosphere Stream (submitted in 2014)
My proposal on Stratosphere Stream (submitted in 2014) My proposal on Stratosphere Stream (submitted in 2014)Born in the big data era, some key ideas behind the design are:
- Flink positions itself as a stream computation engine: it doesn’t provide data persistence capability. Instead, it focuses on providing real-time data processing ability across thousands of machines. To achieve this, Flink follows the design of MapReduce and provides the users with a set of low-level programming APIs (in Java) that can be used to implement parallel and distributed algorithms on a large cluster.
- Flink is natively designed for the big data stack: it heavily relies on various big data services (such as Zookeeper, HDFS, and Yarn), and can be perfectly integrated with other big data systems (such as Cassandra and HBase)*. Just like MapReduce, Flink adopts the shared-nothing architecture, where each machine stores and processes its own data and is entirely independent of other machines.
- By coupling the compute and storage, Flink can obtain extreme scalability, but its elasticity becomes much harder to achieve and manage. Using Flink to empower streaming applications can be super expensive. The system users may have to continuously provide their resources to peak capacity to avoid latency spikes during workload fluctuation.
Flink stands the test of time as reflected by its popularity in the big data world over the past decade. However, when entering the cloud era, everyone is looking for simple and affordable solutions in the cloud. Flink may no longer be the best answer for stream processing. That's what motivated us to build a new cloud-native streaming system. And RisingWave was born!
What is RisingWave?
RisingWave is a cloud-native streaming database built from scratch. I initiated the project in early 2021 after signing off from Amazon Redshift. RisingWave is now open-sourced under Apache License 2.0 after over 15 months of development, and we're building the project with the open-source community.
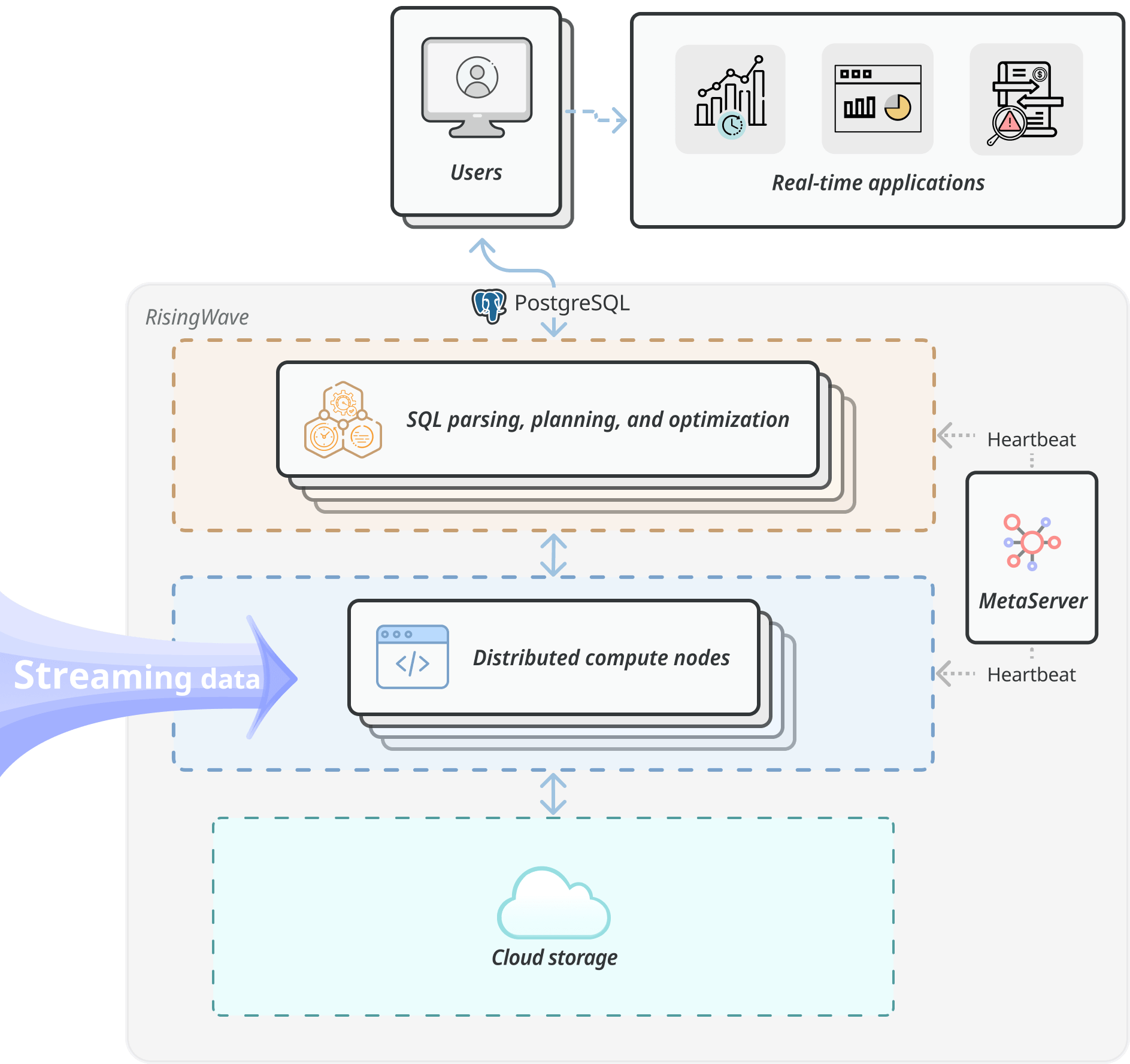 The internal architecture of RisingWave The internal architecture of RisingWave
The internal architecture of RisingWave The internal architecture of RisingWaveTo simplify stream processing, we revisited an old line of research: streaming databases. The idea of streaming databases dates back to an early proposal of data stream management systems (DSMSs) to manage data streams the same way as data management in a database. RisingWave, like many other databases, can ingest data, store data, and answer concurrent access requests from end-users. All these requests can be expressed by PostgreSQL-style SQL.
More than just a SQL database system, RisingWave offers the capability of stream processing: it consumes streaming data, performs continuous queries, and maintains results dynamically in the form of a materialized view. Processing data streams inside a database is quite different from that inside a stream computation engine: streaming data are instantly ingested into data tables; queries over streaming and historical data are simply modeled as table joins; query results are directly maintained and updated inside the database, without pushing into a downstream system.
RisingWave is built on top of the modern cloud infrastructure. A key advantage brought by the cloud infrastructure is that RisingWave can scale compute and storage resources separately and infinitely based on the users’ demands. This offers the chance to constantly attain an optimal cost-performance ratio based on the streaming workload. To fully unleash the power of the cloud infrastructure, RisingWave also adopts a tiered architecture: the compute and storage layers are fully decoupled, allowing on-demand scaling, and a special caching layer is added in the middle of these two layers, thus reducing the frequency of remote storage access.
How is RisingWave different from Flink?
Now let’s get back to our question: how is RisingWave different from Flink? Although both RisingWave and Apache Flink provide stream processing capability for real-time applications, they are different in many ways:
Position
Flink is a stream computation engine that enables users to process streaming data. It does not persist user data and is not optimized for serving concurrent queries issued from users.
RisingWave at its heart is a database system that can consume data and serve queries from end-users. More than a conventional SQL database, RisingWave excels in offering the capability of processing streaming data at low latency.
Objective
Flink was designed to maximize performance given a fixed amount of resources. Its compute-storage-coupled architecture enables it to achieve infinite scaling at a high cost.
RisingWave cares about performance. On top of that, RisingWave is tailored for optimizing the cost efficiency. It adopts a tiered architecture that fully utilizes the cloud resources to give the users fine-grained control over cost and performance.
Interface
Flink natively provides a low-level Java API. While the low-level API offers experts the ability to fully control the underlying dataflow, it is tough to develop and debug, especially for system amateurs. Flink also provides SQL interfaces, but its big-data dialect requires users to pay special attention when writing any SQL queries.
RisingWave offers a standard SQL interface that is compatible with PostgreSQL. Users can process data streams in the same way as they use PostgreSQL.
Ecosystem
Flink is a big data system deeply integrated with the big data ecosystem. Users need to deploy Flink with other open-source big data systems, such as Zookeeper, HDFS, and Yarn.
RisingWave, however, is a cloud-native system that is fully integrated with the cloud ecosystem. RisingWave serves as an integral part of the modern data stack: users can connect RisingWave with any of their favorite systems in the cloud, such as Apache Kafka, Apache Pulsar, Redpanda, Amazon Kinesis, and many others. RisingWave’s wire compatibility with PostgreSQL further allows users to access the prosperous PostgreSQL ecosystem.
Operation
Flink is fairly difficult and expensive to operate since it is deeply rooted in the big data stack. Operating Flink essentially requires users to use several systems, including Zookeeper, HDFS, and many others. Users may have to manually reconfigure the system to achieve higher efficiency in confronting workload fluctuation.
The cloud-native design of RisingWave dramatically lowers the bar for system operations. RisingWave does not depend on any big data services, and its decoupled compute and storage architecture vastly simplifies the management of elasticity.
Target Users
Flink’s target users are mostly data engineers and experts. The operation cost and the learning curve make it difficult for amateur users to fully harness the power of Flink.
RisingWave targets not only engineers but also data scientists, analysts, decision-makers, and anyone who needs fresh results. It can be easily deployed and maintained in the cloud, and elasticity can be achieved with little human interference. Its PostgreSQL-style SQL also makes it simple for users to program their streaming applications.
Conclusion
Flink is a big data engine, whereas RisingWave is a cloud database.
RisingWave is not the next Flink. It is the answer for stream processing in the cloud era.
We believe that a great product comes from the combined wisdom of a vibrant and open community. Check out the source code at GitHub to get involved, and join our Slack community for lively discussions!
Note
*This was true historically, but more and more users are moving towards Kubernetes with some distributed file systems or object stores for persistent storage. The Hadoop ecosystem has already been made completely optional in the classpath. The Apache Flink community is intentionally facilitating this, with efforts like https://github.com/apache/flink-kubernetes-operator. Credit to






